01
Routing math computation through a verified solver
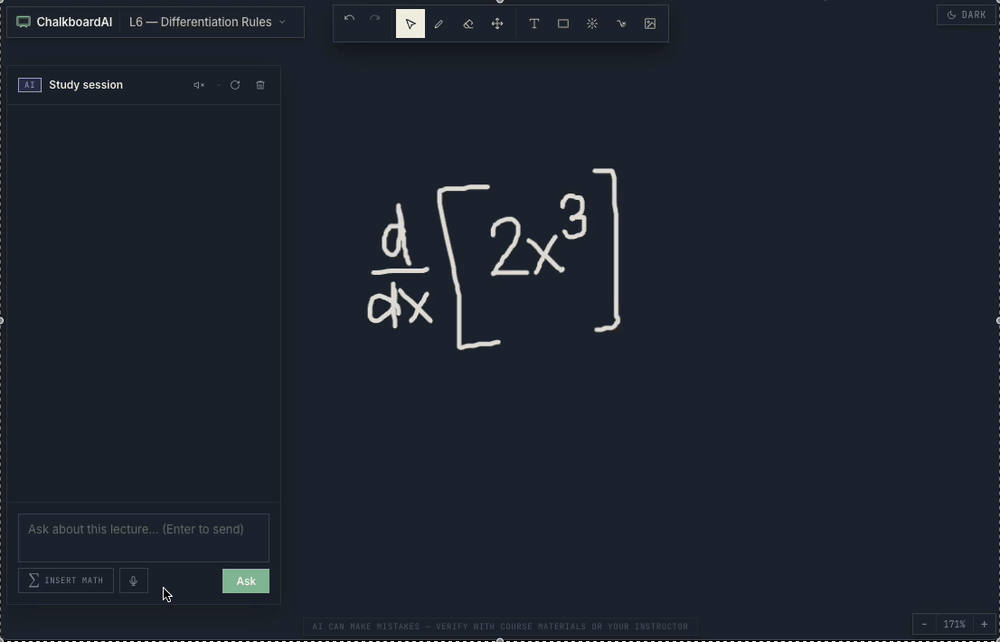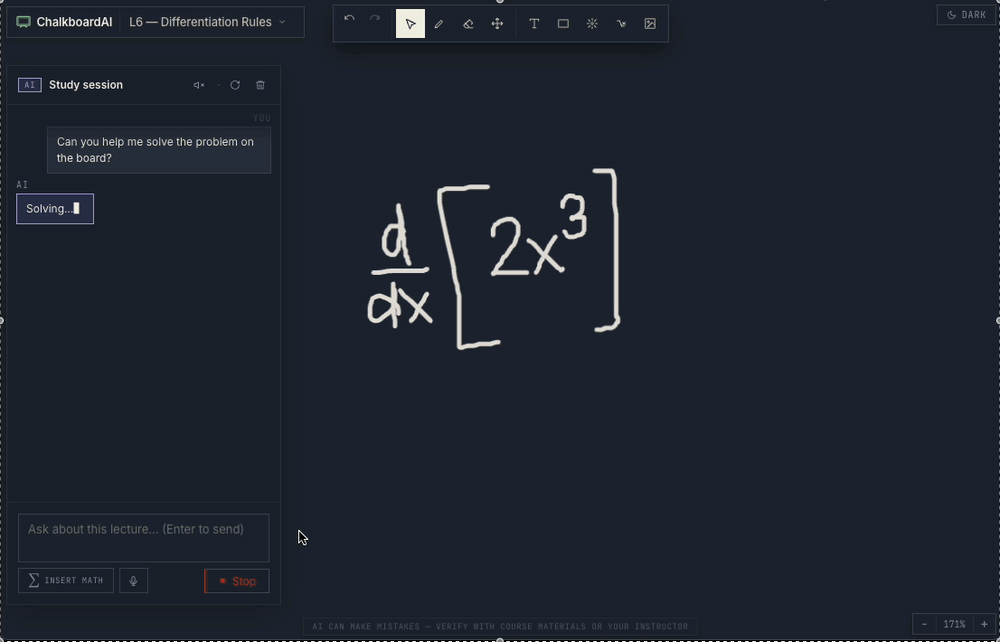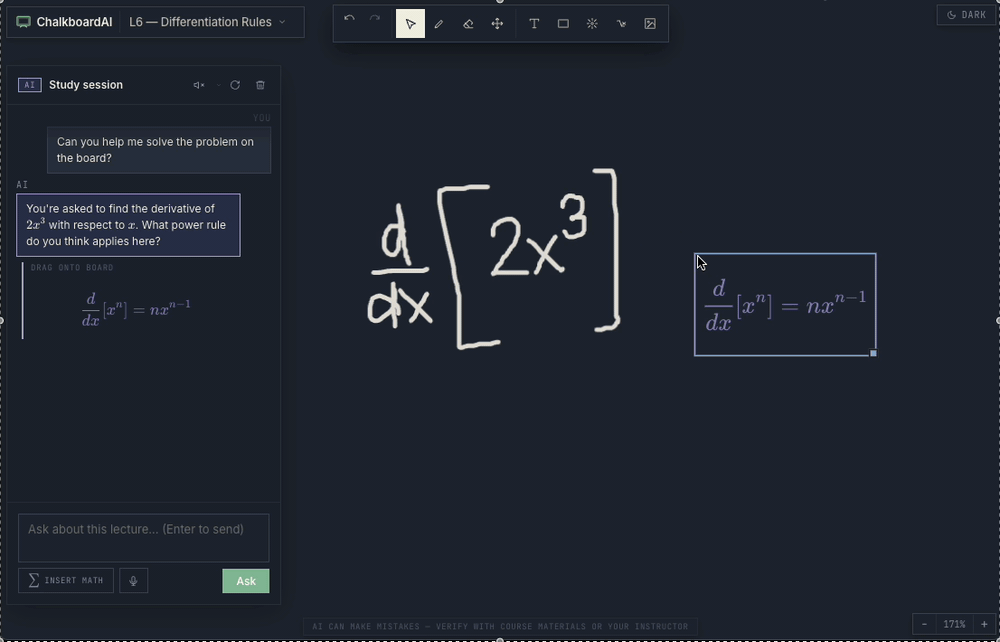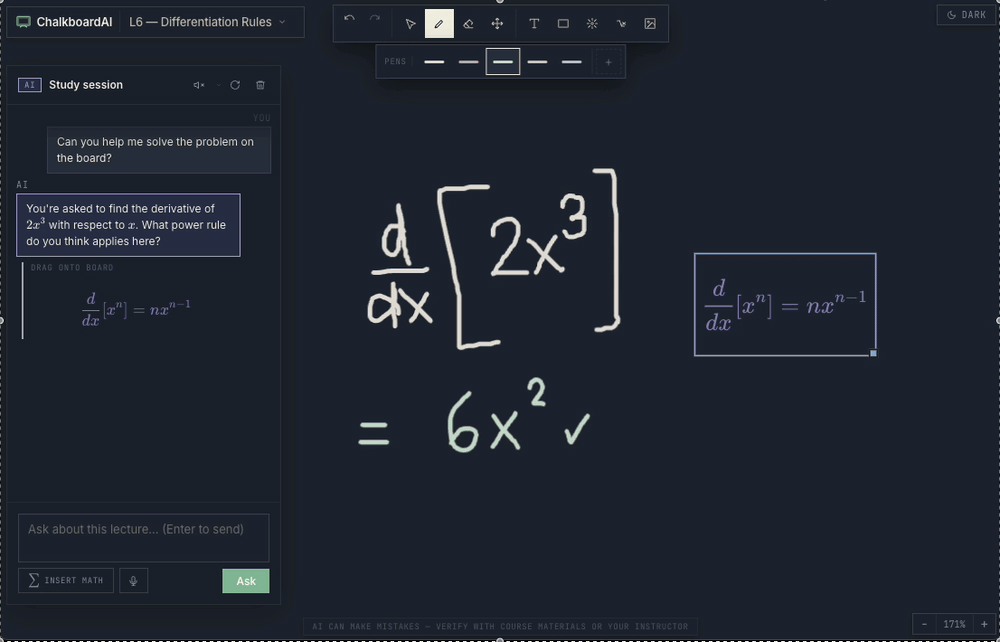
The base LLM could not be trusted to do arithmetic. On the same problem (the limit of f(x) = 12 − 5x as x approaches 2, answer: 2), it returned 7, then 3, then −8 in a single session. A math tutor that gets the math wrong is worse than no tutor at all.
Better prompting wouldn't fix it; the model was just computing badly. I connected the model to a math solver for computation, so the LLM handles reasoning and explanation while verified tool calls handle the arithmetic. The model went from three wrong answers on one problem to consistent accuracy on the same class of questions.
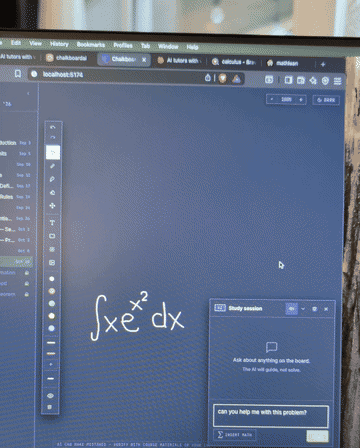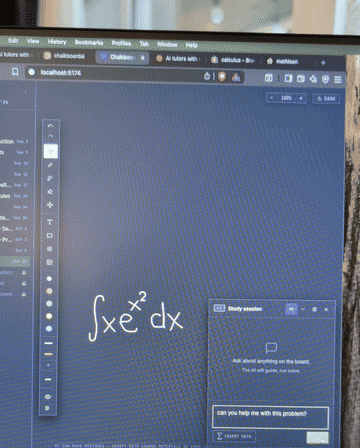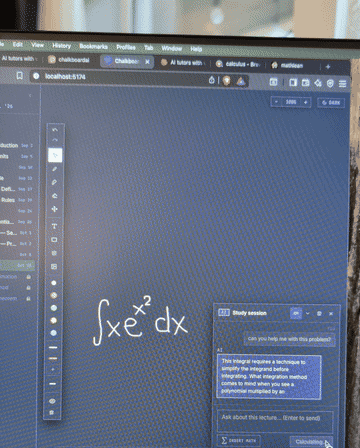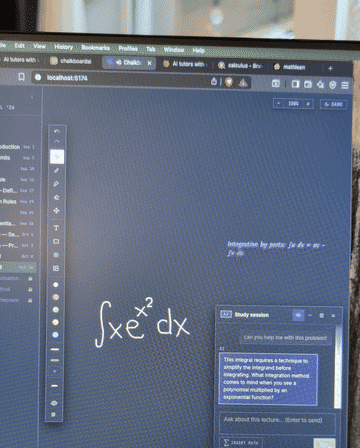
What I learned. When the failure is at the model's core capability, prompting harder is the wrong move. Tool use is the right one.